6 The query system
This chapter describes the newly implemented query system of the emuR package. When developing the new emuR package it was essential that it had a query mechanism allowing users to query a database’s annotations in a simple manner. The EMU query language (EQL) of the EMU-SDMS arose out of years of developing and improving upon the query language of the legacy system (e.g., Cassidy and Harrington (2001), Harrington (2010), John (2012)). As a result, today we have an expressive, powerful, yet simple to learn and domain-specific query language. The EQL defines a user interface by allowing the user to formulate a formal language expression in the form of a query string. The evaluation of a query string results in a set of annotation items or, alternatively, a sequence of items of a single annotation level in the emuDB from which time information, if applicable (see Section 6.2.6), has been deduced from the time-bearing sub-level. An example of this is a simple query that extracts all strong syllables (i.e., syllable annotation items containing the label S on the Syllable level) from a set of hierarchical annotations (see Figure 6.1 for an example of a hierarchical annotation). The respective EQL query string "Syllable == S" results in a set of segments containing the annotation label S. Due to the temporal inclusion constraint of the domination relationship, the start and end times of the queried segments are derived from the respective items of the Phonetic level (i.e., the m and H nodes in Figure 6.1, as this is the time-bearing sub-level. The EQL described here allows users to query the complex hierarchical annotation structures in their entirety as they are described in Chapter 4.
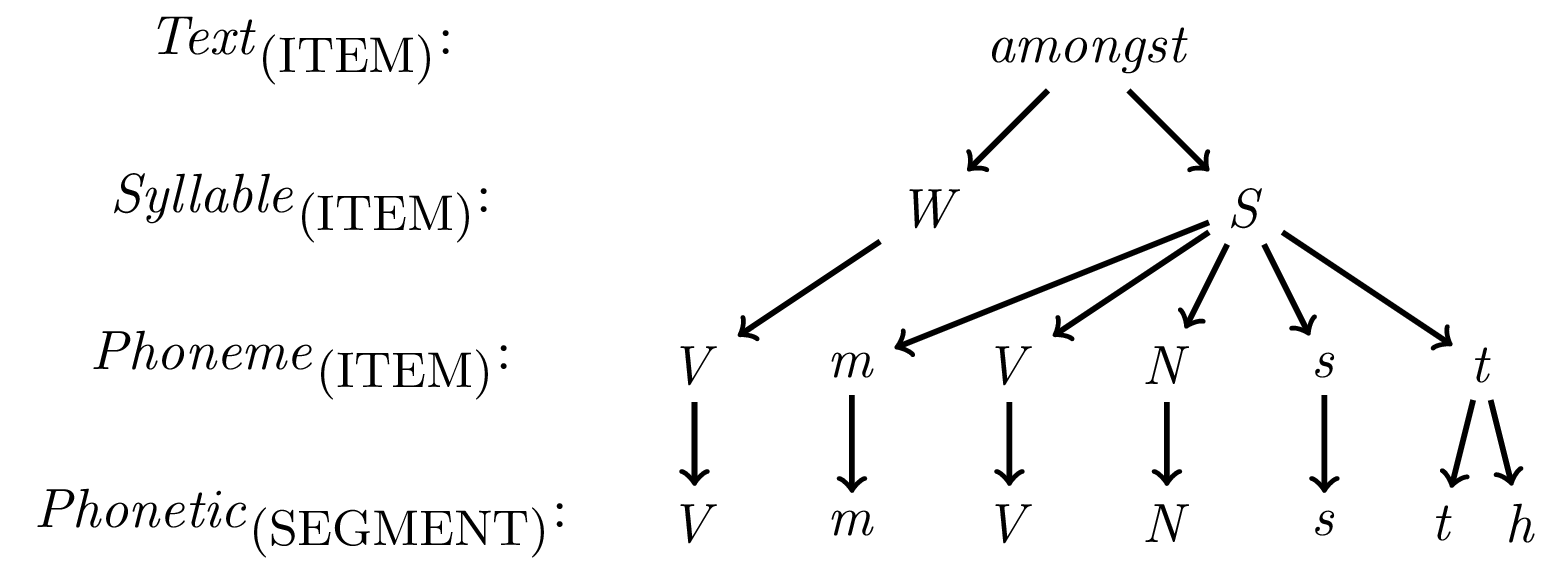
Figure 6.1: Simple partial hierarchy of an annotation of the word amongst in the msajc003 bundle in the ae demo emuDB.
The R code snippet below shows how to create the demo data that is provided by the emuR package followed by loading an example emuDB called ae into the current R session. This database will be used in all the examples throughout this chapter.
# load package
library(emuR)
# create demo data in directory
# provided by tempdir()
create_emuRdemoData(dir = tempdir())
# create path to demo database
path2ae = file.path(tempdir(), "emuR_demoData", "ae_emuDB")
# load database
# (verbose = F is only set to avoid additional output in manual)
ae = load_emuDB(path2ae, verbose = F)6.1 The resulting object of a query
In emuR the result of a query or requery (see Section 6.2.7) is an object of the popular type tibble (see also https://tidyverse.org/) which is a superclass of the common data.frame. R code snippet below shows the result of a slightly expanded version of the above query ("Syllable == S"), which additionally uses the dominates operator (i.e., the ^ operator; for further information see Section 6.2.2.4) to reduce the queried annotations to the partial hierarchy depicted in Figure 6.1 in the ae demo emuDB. In this example, the classes of the resulting object including its printed output are displayed. The printed output provides information about the labels, start and end times (in milliseconds), session, bundle, level and attribute among other information which is predominantly used to store information about what the exact items or sequence of items were retrieved from the emuDB. This information is needed to know which items to start from in a requery (see Section 6.2.7) and is also the reason why the resulting object should be viewed as a reference of sequences of annotation items that belong to a single level in all annotation files of an emuDB.
# query database
sl = query(ae, "[Syllable == S ^ Text == amongst]")
# show class vector
class(sl)## [1] "tbl_df" "tbl" "data.frame"# show sl object
sl## # A tibble: 1 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 S 257. 674. 0fc618… 0000 msajc… 103 103 Syll…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>6.2 EQL: The EMU Query Language version 2
The EQL user interface was retained from the legacy system because it was sufficiently flexible and expressive enough to meet the query needs in most types of speech science research. The EQL parser implemented in emuR is based on the Extended Backus–Naur form (EBNF) (Garshol 2003) formal language definition of John (2012), which defines the symbols and the relationship of those symbols to each other on which this language is built (see adapted version of entire EBNF in Appendix 17). Here we will describe the various terms and components that comprise the slightly adapted version 2 of the EQL. It is worth noting that the new query mechanism uses a relational back-end to handle the various query operations (see Chapter 11 for details). This means that expert users, who are proficient in Structured Query Language (SQL) may also query this relational back-end directly. However, we feel the EQL provides a simple abstraction layer which is sufficient for most speech and spoken language research.
6.2.1 Simple queries
The most basic form of an EQL query is a simple equality, inequality, matching or non-matching query, two of which are displayed in R code snippet below. The syntax of a simple query term is [L OPERATOR A], where L specifies a level (or alternatively the name of a parallel attribute definition); OPERATOR is one of == (equality), != (inequality), =~ (matching) or !~ (non-matching); and A is an expression specifying the labels of the annotation items of L.13 The second query in the R code snippet below queries an event level. The result of querying an event level contains the same information as that of a segment level query except that the derived end times have the value zero.
# query all annotation items containing
# the label "m" on the "Phonetic" level
query(ae, "Phonetic == m")## # A tibble: 7 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m 257. 340. 0fc618… 0000 msajc… 148 148 Phon…
## 2 m 1490. 1565. 0fc618… 0000 msajc… 169 169 Phon…
## 3 m 497. 559. 0fc618… 0000 msajc… 188 188 Phon…
## 4 m 1587. 1656. 0fc618… 0000 msajc… 149 149 Phon…
## 5 m 819. 903. 0fc618… 0000 msajc… 120 120 Phon…
## 6 m 1630. 1709. 0fc618… 0000 msajc… 185 185 Phon…
## 7 m 2173. 2233. 0fc618… 0000 msajc… 194 194 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int># query all items NOT containing the
# label "H*" on the "Tone" level
query(ae, "Tone != H*")## # A tibble: 34 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 L- 1107 0 0fc618… 0000 msajc… 183 183 Tone
## 2 L- 2543. 0 0fc618… 0000 msajc… 186 186 Tone
## 3 L% 2578. 0 0fc618… 0000 msajc… 187 187 Tone
## 4 L- 1012. 0 0fc618… 0000 msajc… 187 187 Tone
## 5 L- 2459. 0 0fc618… 0000 msajc… 190 190 Tone
## 6 L% 2490. 0 0fc618… 0000 msajc… 191 191 Tone
## 7 !H* 836. 0 0fc618… 0000 msajc… 188 188 Tone
## 8 L- 973. 0 0fc618… 0000 msajc… 189 189 Tone
## 9 L- 1558. 0 0fc618… 0000 msajc… 191 191 Tone
## 10 !H* 2151. 0 0fc618… 0000 msajc… 193 193 Tone
## # … with 24 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>The R code snippet above queries two levels that contain time information: a segment level and an event level. As described in Chapter 4, annotations in the EMU-SDMS may also contain levels that do not contain time information. The R code snippet below shows a query that queries annotation items on a level that does not contain time information (the Syllable level) to show that the result contains deduced time information from the time-bearing sub-level.
# query all annotation items containing
# the label S on the Syllable level
query(ae, "Syllable == S")## # A tibble: 37 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 S 257. 674. 0fc618… 0000 msajc… 103 103 Syll…
## 2 S 674. 740. 0fc618… 0000 msajc… 104 104 Syll…
## 3 S 740. 1289. 0fc618… 0000 msajc… 105 105 Syll…
## 4 S 1791. 1945. 0fc618… 0000 msajc… 109 109 Syll…
## 5 S 2034. 2284. 0fc618… 0000 msajc… 111 111 Syll…
## 6 S 572. 798. 0fc618… 0000 msajc… 107 107 Syll…
## 7 S 798. 1091. 0fc618… 0000 msajc… 108 108 Syll…
## 8 S 1222. 1391. 0fc618… 0000 msajc… 110 110 Syll…
## 9 S 1437. 1515. 0fc618… 0000 msajc… 112 112 Syll…
## 10 S 1628. 1864. 0fc618… 0000 msajc… 114 114 Syll…
## # … with 27 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>6.2.1.1 Queries using regular expressions
The slightly expanded version 2 of the EQL, which comes with the emuR package, introduces regular expression operators (=~ and !~). These allow users to formulate regular expressions for more expressive and precise pattern matching of annotations. A minimal set of examples displaying the new regular expression operators is shown in Table 6.1.
| Query | Function |
|---|---|
Phonetic =~ '[AIOUEV]'
|
A disjunction of annotations using a RegEx character class |
Word =~ a.*
|
All words beginning with a |
Word !~ .*st
|
All words not ending in st |
[Phonetic == n ^ #Syllable =~ .*]
|
All syllables that dominate an n segment of the Phonetic level |
6.2.2 Combining simple queries
The EQL contains three operators that can be used to combine the simple query terms described above as well as position queries which we will describe below. These three operators are the sequence operator, ->; the conjunction operator, &; and the domination operator, ^, which is used to perform hierarchical queries. These three types of queries are described below. To start with, we describe the two types of queries that query more complex annotation structures on the same level (sequence and conjunction queries). This is followed by a description of domination queries that query hierarchically linked annotation structures, sometimes spanning multiple annotation levels.
6.2.2.1 Sequence queries
The syntax of a query string using the -> sequence operator is [L == A -> L == B] where annotation item A on level L precedes item B on level L. For a sequence query to work, both arguments must be on the same level. Alternatively parallel attribute definitions of the same level may also be chosen (see Chapter 4 for further details). An example of a query string using the sequence operator is displayed in the R code snippet below. All rows in the resulting segment list have the start time of @, the end time of n and their labels are @->n, where the -> substring denotes the sequence.
# query all sequences of items on the "Phonetic" level
# in which an item containing the label "@" is followed by
# an item containing the label "n"
query(ae, "[Phonetic == @ -> Phonetic == n]")## # A tibble: 6 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 @->n 1715. 1791. 0fc618… 0000 msajc… 167 168 Phon…
## 2 @->n 2382. 2528. 0fc618… 0000 msajc… 183 184 Phon…
## 3 @->n 2356. 2475. 0fc618… 0000 msajc… 181 182 Phon…
## 4 @->n 2201. 2271. 0fc618… 0000 msajc… 215 216 Phon…
## 5 @->n 1422. 1495. 0fc618… 0000 msajc… 126 127 Phon…
## 6 @->n 2407. 2480. 0fc618… 0000 msajc… 198 199 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>6.2.2.2 Result modifier
Because users are often interested in just one element of a compound query such as sequence queries (e.g., the @s in a @->n sequences), the EQL offers a so-called result modifier symbol, #. This symbol may be placed in front of any simple query component of a multi component query as depicted in the R code snippet below. Placing the hashtag in front of either the left or the right simple query term will result in segment lists that contain only the annotation items of the simple query term that have the hashtag in front of it. Only one result modifier may be used per query.
# query the "@"s in "@->n" sequences
query(ae, "[#Phonetic == @ -> Phonetic == n]")## # A tibble: 6 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 @ 1715. 1741. 0fc618… 0000 msajc… 167 167 Phon…
## 2 @ 2382. 2431. 0fc618… 0000 msajc… 183 183 Phon…
## 3 @ 2356. 2402. 0fc618… 0000 msajc… 181 181 Phon…
## 4 @ 2201. 2227. 0fc618… 0000 msajc… 215 215 Phon…
## 5 @ 1422. 1435. 0fc618… 0000 msajc… 126 126 Phon…
## 6 @ 2407. 2448. 0fc618… 0000 msajc… 198 198 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int># query the "n"s in a "@->n" sequences
query(ae, "[Phonetic == @ -> #Phonetic == n]")## # A tibble: 6 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 n 1741. 1791. 0fc618… 0000 msajc… 168 168 Phon…
## 2 n 2431. 2528. 0fc618… 0000 msajc… 184 184 Phon…
## 3 n 2402. 2475. 0fc618… 0000 msajc… 182 182 Phon…
## 4 n 2227. 2271. 0fc618… 0000 msajc… 216 216 Phon…
## 5 n 1435. 1495. 0fc618… 0000 msajc… 127 127 Phon…
## 6 n 2448. 2480. 0fc618… 0000 msajc… 199 199 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>6.2.2.3 Conjunction queries
The syntax of a query string using the conjunction operator can schematically be written as: [L_a1 == A & L_a2 == B & L_a3 == C & L_a4 == D & ... & L_an == N], where annotation items on level L have the label A and also have the parallel labels B, C, D, …, N (see Chapter 4 for more information about parallel labels). By analogy with the sequence operator, all simple query statements must refer to the same level (i.e., only parallel attributes definitions of the same level indicated by the a1 - an may to be chosen). Hence, the conjunction operator is used to combine query conditions on the same level. Using the conjunction operator is useful for two reasons:
- It combines different attributes of the same level:
[Text == always & Accent == S]where Text and Accent are additional attributes of level Word; and - It combines a simple query with a function query (see Position Queries Section 6.2.3): [Phonetic == l & Start(Word, Phonetic) == 1].
An example of a query string using the conjunction operator is displayed in the R code snippet below.
# query all words with the orthographic transcription "always"
# that also have a strong word accent ("S")
query(ae, "[Text == always & Accent == S]")## # A tibble: 1 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 always 775. 1280. 0fc618… 0000 msajc… 28 28 Word
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>The above R code snippet does not make use of the result modifier symbol. However, only the annotation items of the left simple query term (Text == always) are returned. This behavior is true for all EQL operators that combine simple query terms except for the sequence operator. As it is more explicit to use the result modifier to express the desired result, we recommend using the result modifier where possible. The more explicit variant of the above query which yields the same result is “[#Text == always & Word == C]”.
6.2.2.4 Domination/hierarchical queries
Compared to sequence and conjunction queries, a domination query using the operator ^ is not bound to a single level. Instead, it allows users to query annotation items that are directly or indirectly linked over one or more levels. Queries using the domination operator are often referred to as hierarchical queries as they provide the ability to query the hierarchical annotations in a vertical or inter-level manner. Figure 6.2 shows the same partial hierarchy as Figure 6.1 but highlights the annotational items that are dominated by the strong syllable (S) of the Syllable level. Such linked hierarchical sub-structures can be queried using hierarchical/domination queries.
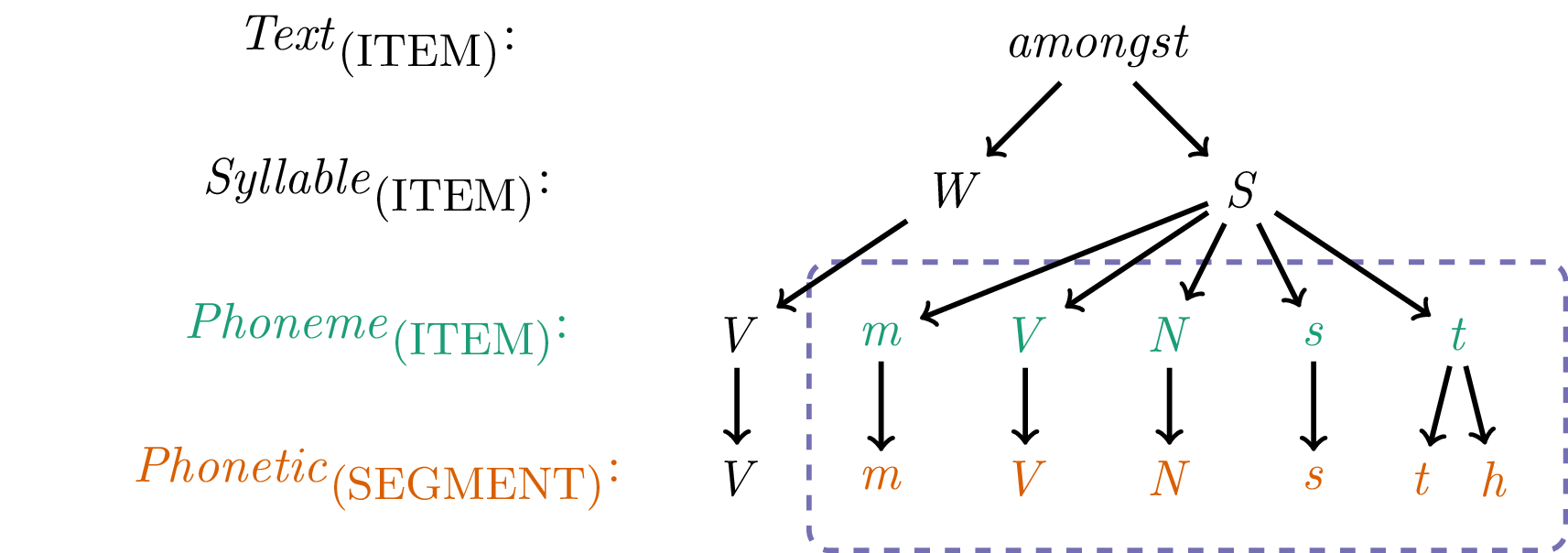
Figure 6.2: Partial hierarchy depicting all annotation items that are dominated by the strong syllable (S) of the Syllable level (inside dashed box). Items marked green belong to the Phoneme level, items marked orange belong to the Phonetic level and the purple dashed box indicates the set of items that are dominated by S.
A schematic representation of a simple domination query string that retrieves all annotation items A of level L1 that are dominated by items B in level L2 (i.e., items that are directly or indirectly linked) is [L1 == A ^ L2 == B]. Although the domination relationship is directed the domination operator is not. This means that either items in L1 dominate items in L2 or items in L2 dominate items in L1. Note that link definitions that specify the validity of the domination have to be present in the emuDB configuration for this to work (see Chapter 5 for details). An example of a query string using the domination operator is displayed in the R code snippet below.
# query all "p" phoneme items that belong
# to / are dominated by a strong syllable ("S")
query(ae, "[Phoneme == p ^ Syllable == S]")## # A tibble: 3 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 p 559. 640. 0fc618… 0000 msajc… 147 147 Phon…
## 2 p 1656. 1699. 0fc618… 0000 msajc… 122 122 Phon…
## 3 p 864. 970. 0fc618… 0000 msajc… 136 136 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>As with the conjunction query, if no result modifier is present, a dominates query returns the annotation items of the left simple query term. Hence, the more explicit variant of the above query is "[#Phoneme == p ^ Syllable == S]".
6.2.3 Position queries
The EQL has three function terms that specify where in a domination relationship a child level annotation item is allowed to occur. The three function terms are Start(), End() and Medial(). A schematic representation of a query string representing a simple usage of the Start(), End() and Medial() function would be: POSFCT(L1, L2) == TRUE. In this representation POSFCT is a placeholder for one of the three functions, at which level L1 must dominate level L2. Where L1 does indeed dominate L2, the corresponding item from level L2 is returned. If the expression is set to FALSE (i.e., POSFCT(L1, L2) == FALSE), all the items that do not match the condition of L2 are returned. An illustration of what is returned by each of the position functions depending on if they are set to TRUE or FALSE is depicted in Figure 6.3, while the R code snippet below shows an example query using a position query term.
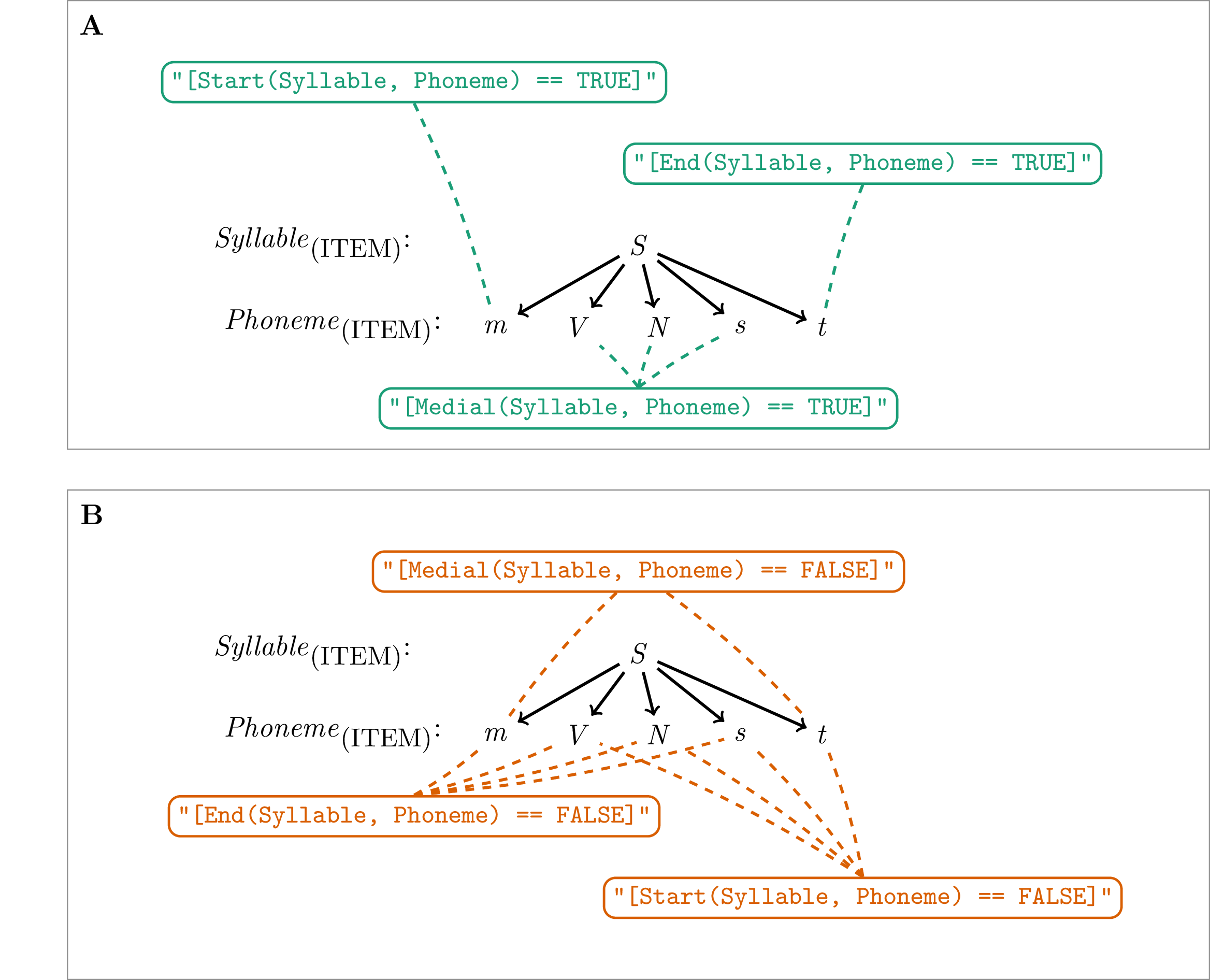
Figure 6.3: Illustration of what is returned by the Start(), Medial() and End() functions depending if they are set to A: TRUE (green) or B: FALSE (orange).
# query all phoneme items that occur
# at the start of a syllable
query(ae, "[Start(Syllable, Phoneme) == TRUE]")## # A tibble: 83 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 V 187. 257. 0fc618… 0000 msajc… 114 114 Phon…
## 2 m 257. 340. 0fc618… 0000 msajc… 115 115 Phon…
## 3 @: 674. 740. 0fc618… 0000 msajc… 120 120 Phon…
## 4 f 740. 893. 0fc618… 0000 msajc… 121 121 Phon…
## 5 S 1289. 1420. 0fc618… 0000 msajc… 126 126 Phon…
## 6 w 1463. 1506. 0fc618… 0000 msajc… 128 128 Phon…
## 7 k 1634. 1715. 0fc618… 0000 msajc… 131 131 Phon…
## 8 s 1791. 1893. 0fc618… 0000 msajc… 134 134 Phon…
## 9 d 1945. 1967. 0fc618… 0000 msajc… 136 136 Phon…
## 10 b 2034. 2150. 0fc618… 0000 msajc… 139 139 Phon…
## # … with 73 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>6.2.4 Count queries
A further query component of the EQL are so-called count queries. They allow the user to specify how many child nodes a parent annotation item is allowed to have. Figure 6.4 displays two syllables, one containing one phoneme and one phonetic annotation item, the other containing five phoneme and six phonetic items. Using EQL’s Num() function it is possible to specify which of the two syllables should be retrieved, depending on the number of phonemic or phonetic elements to which it is directly or indirectly linked. The R code snippet below shows a query that queries all syllables that contain five phonemes.
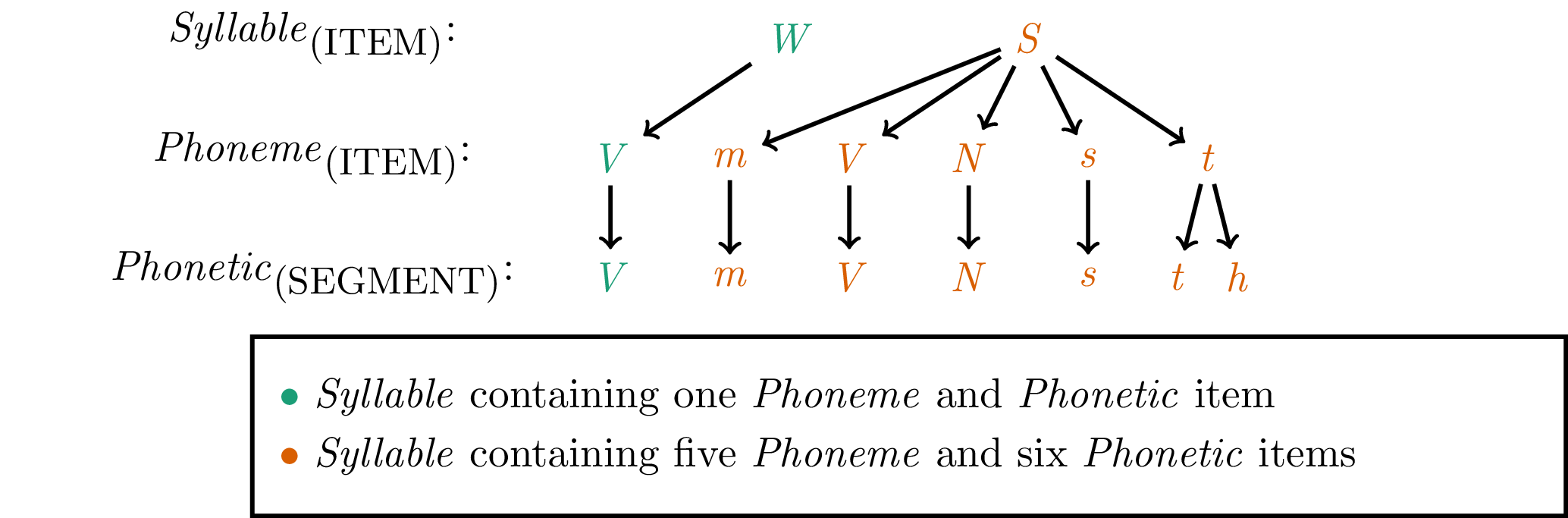
Figure 6.4: Partial hierarchy depicting a Syllable containing one Phoneme and Phonetic item (green) and a Syllable containing five Phoneme and six Phonetic items (orange).
A schematic representation of a query string utilizing the count mechanism would be [Num(L1, L2) == N], where L1 contains N annotation items in L2. For this type of query to work L1 has to dominate L2 (i.e., be a parent level to L2). As the query matches a number (N), it is also possible to use the operators > (more than), < (less than) and != (not equal to). The resulting segment list contains items of L1.
# retrieve all syllables that contain five phonemes
query(ae, "[Num(Syllable, Phoneme) == 5]")## # A tibble: 5 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 S 257. 674. 0fc618… 0000 msajc… 103 103 Syll…
## 2 S 740. 1289. 0fc618… 0000 msajc… 105 105 Syll…
## 3 W 2228. 2754. 0fc618… 0000 msajc… 118 118 Syll…
## 4 S 1890. 2470. 0fc618… 0000 msajc… 105 105 Syll…
## 5 S 1964. 2554. 0fc618… 0000 msajc… 90 90 Syll…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>6.2.5 More complex queries
By using the correct bracketing, all of the above query components can be combined to formulate more complex queries that can be used to answer questions such as: Which occurrences of the word “his” follow three-syllable words which contain a schwa (@) in the first syllable? Such multi-part questions can usually be broken down into several sub-queries. These sub-queries can then be recombined to formulate the complex query. The steps to answering the above multi-part question are:
- Which occurrences of the word “his” …:
[Text == his] - … three-syllable words …:
[Num(Text, Syllable) == 3] - … contain a schwa (@) in the first syllable …:
[Phoneme == @ ^ Start(Word, Syllable) == 1] - All three can be combined by saying 2 dominates 3 (
[2 ^ 3]) and these are followed by 1 ([2 ^ 3] -> 1])
The combine query is depicted in the R code snippet below. This complex query demonstrates the expressive power of the query mechanism that the EMU-SDMS provides.
# perform complex query
# Note that the use of paste0() is optional, as
# it is only used for formatting purposes
query(ae, paste0("[[[Num(Text, Syllable) == 3] ",
"^ [Phoneme == @ ^ Start(Word, Syllable) == 1]] ",
"-> #Text = his]"))## # A tibble: 1 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 his 2694. 2781. 0fc618… 0000 msajc… 101 101 Word
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>As mastering these complex compound queries can require some practice, several simple as well as more complex examples that combine the various EQL components described above are available in Appendix 18. These examples provide practical examples to help users find queries suited to their needs.
6.2.6 Deducing time
The default behavior of the legacy EMU system was to automatically deduce time information for queries of levels that do not contain time information. This was achieved by searching for the time-bearing sub-level and calculating the start and end times from the left-most and right-most annotation items which where directly or indirectly linked to the retrieved parent item. This upward purculation of time information is also the default behavior of the new EMU-SDMS. However, a new feature has been added to the query engine which allows the calculation of time to be switched off for a given query using the calcTimes parameter of the query() function. This is beneficial in two ways: for one, levels that do not have a time-bearing sub-level may be queried and secondly, the execution time of queries can be greatly improved. The performance increase becomes evident when performing queries on large data sets on one of the top levels of the hierarchy (e.g., Utterance or Intonational in the ae emuDB). When deducing time information for annotation items that contain large portions of the hierarchy, the query engine has to walk down large partial hierarchies to find the left-most and right-most items on the time-bearing sub-level. This can be a computationally expensive operation and is often unnecessary, especially during data exploration. The R code snippet below shows the usage of this parameter by querying all of the items of the Intonational level and displaying the NA values for start and end times in the resulting segment list. It is worth noting that the missing time information excluded during the original query can be retrieved at a later point in time by performing a hierarchical requery (see Section 6.2.7) on the same level.
# query all intonational items
query(ae, "Intonational =~ .*", calcTimes = F)## # A tibble: 7 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 L% NA NA 0fc618… 0000 msajc… 7 7 Into…
## 2 L% NA NA 0fc618… 0000 msajc… 7 7 Into…
## 3 L% NA NA 0fc618… 0000 msajc… 7 7 Into…
## 4 L% NA NA 0fc618… 0000 msajc… 7 7 Into…
## 5 L% NA NA 0fc618… 0000 msajc… 7 7 Into…
## 6 L% NA NA 0fc618… 0000 msajc… 7 7 Into…
## 7 L% NA NA 0fc618… 0000 msajc… 7 7 Into…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>6.2.7 Requery
A popular feature of the legacy system was the ability to use the result of a query to perform an additional query, called a requery, starting from the resulting items of a query. The requery functionality was used to move either sequentially (horizontally) or hierarchically (vertically) through the hierarchical annotation structure. Although this feature technically does not extend the querying functionality (it is possible to formulate EQL queries that yield the same results as a query followed by \(1:n\) requeries), requeries benefit the user by breaking down the task of formulating long query terms into multiple, simpler queries. Compared with the legacy system, this feature is implemented in the emuR package in a more robust way, as unique item IDs are present in the result of a query, eliminating the need for searching the starting segments based on their time information. Examples of queries and their results within a hierarchical annotation based on a hierarchical and sequential requery as well as their EQL equivalents are illustrated in Figure 6.5.
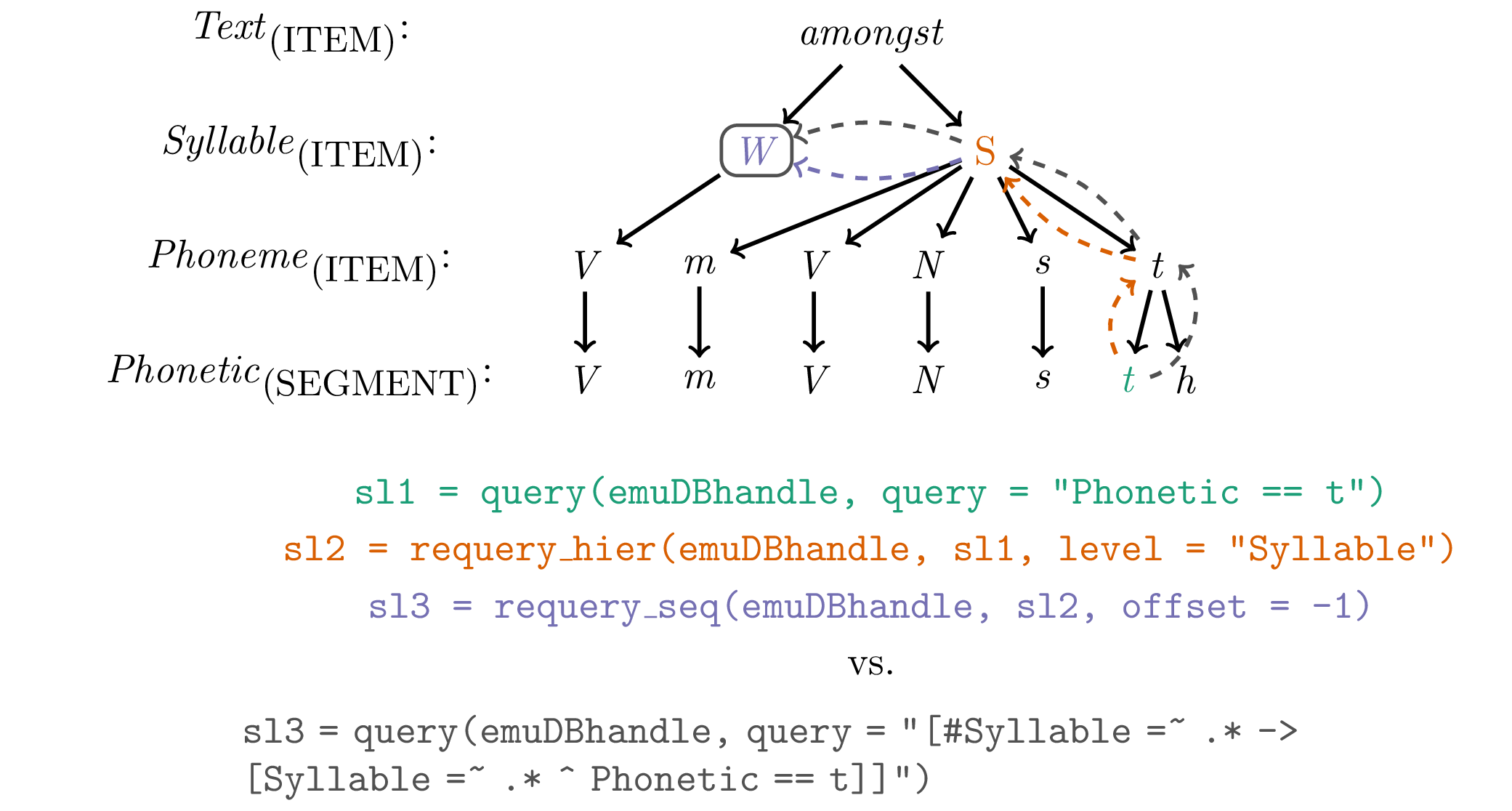
Figure 6.5: Three-step (query (green) -> requery_hier (orange) -> requery_seq (purple)) requery procedure, its single query (grey) counterpart and their color coded movements within the annotation hierarchy.
The R code snippet below illustrates how the same results of the sequential query [#Phonetic =~ .* -> Phonetic == n] can be achieved using the requery_seq() function. Further, it shows how the requery_hier() function can be used to move vertically through the annotation structure by starting at the Syllable level and retrieving all the Phonetic items for the query result.
########################
# requery_seq()
# query all "n" phonetic items
sl_n = query(ae, "Phonetic == n")
# sequential requery (left shift result by 1 (== offset of -1))
# and hence retrieve all phonetic items directly preceeding
# all "n" phonetic items
requery_seq(ae,
seglist = sl_n,
offset = -1)## # A tibble: 12 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 E 950. 1032. 0fc618… 0000 msajc… 157 157 Phon…
## 2 @ 1715. 1741. 0fc618… 0000 msajc… 167 167 Phon…
## 3 E 1437. 1515. 0fc618… 0000 msajc… 169 169 Phon…
## 4 @ 2382. 2431. 0fc618… 0000 msajc… 183 183 Phon…
## 5 I 812. 895. 0fc618… 0000 msajc… 157 157 Phon…
## 6 @ 2356. 2402. 0fc618… 0000 msajc… 181 181 Phon…
## 7 @ 2201. 2227. 0fc618… 0000 msajc… 215 215 Phon…
## 8 H 3027. 3046. 0fc618… 0000 msajc… 228 228 Phon…
## 9 @ 1422. 1435. 0fc618… 0000 msajc… 126 126 Phon…
## 10 k 1705. 1775. 0fc618… 0000 msajc… 131 131 Phon…
## 11 On 476. 509. 0fc618… 0000 msajc… 165 165 Phon…
## 12 @ 2407. 2448. 0fc618… 0000 msajc… 198 198 Phon…
## # … with 7 more variables: attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>########################
# requery_hier()
# query all strong syllables (S)
sl_s = query(ae, "Syllable == S")
# hierarchical requery
requery_hier(ae,
seglist = sl_s,
level = "Phonetic")## # A tibble: 37 x 16
## labels start end db_uuid session bundle start_item_id end_item_id level
## <chr> <dbl> <dbl> <chr> <chr> <chr> <int> <int> <chr>
## 1 m->V-… 257. 674. 0fc618… 0000 msajc… 148 153 Phon…
## 2 @: 674. 740. 0fc618… 0000 msajc… 154 154 Phon…
## 3 f->r-… 740. 1289. 0fc618… 0000 msajc… 155 159 Phon…
## 4 s->I 1791. 1945. 0fc618… 0000 msajc… 169 170 Phon…
## 5 db->j… 2034. 2284. 0fc618… 0000 msajc… 173 175 Phon…
## 6 f->j-… 572. 798. 0fc618… 0000 msajc… 156 158 Phon…
## 7 t->H-… 798. 1091. 0fc618… 0000 msajc… 159 162 Phon…
## 8 O->f 1222. 1391. 0fc618… 0000 msajc… 166 167 Phon…
## 9 E 1437. 1515. 0fc618… 0000 msajc… 169 169 Phon…
## 10 f->@: 1628. 1864. 0fc618… 0000 msajc… 172 173 Phon…
## # … with 27 more rows, and 7 more variables: attribute <chr>,
## # start_item_seq_idx <int>, end_item_seq_idx <int>, type <chr>,
## # sample_start <int>, sample_end <int>, sample_rate <int>6.3 Discussion
This chapter gave an overview of the abilities of the query system of the EMU-SDMS. We feel the EQL is an expressive, powerful, yet simple to learn and domain-specific query language that allows users to adequately query complex annotation structures. Further, the query system provided by the EMU-SDMS surpasses the querying capabilities of most commonly used systems. As the result of a query is a superclass of the common data.frame object, these results can easily be further processed using various R functions (e.g., to remove unwanted segments). Further, the results of queries can be used as input to the get_trackdata() function (see Chapter 7) which makes the query system a vital part in the default workflow described in Chapter 2.
Although the query mechanism of the EMU-SDMS covers most linguistic annotation query needs (including co-occurrence and domination relationship child position queries), it has limitations due to its domain-specific nature, its simplicity and its predefined result type. Performing more general queries such as: What is the average age of the male speakers in the database who are taller than 1.8 meters? is not directly possible using the EQL. Even if the gender, height and age parameters are available as part of the database’s annotations (e.g., using the single bundle root node metadata strategy described in Chapter 4) they would be encoded as strings, which do not permit direct calculations or numerical comparisons. However, it is possible to answer these types of questions using a multi-step approach. One could, for example, extract all height items and convert the strings into numbers to filter the items containing a label that is greater than 1.8. These filtered items could then be used to perform two requeries to extract all male speakers and their age labels. These age labels could once again be converted into numbers to calculate their average. Although not as elegant as other languages, we have found that most questions that arise as part of studies working with spoken language database can be answered using such a multi-step process including some data manipulation in R, provided the necessary information is encoded in the database. Additionally, from the viewpoint of a speech scientist, we feel that the intuitiveness of an EQL expression (e.g., a query to extract the sibilant items for the question asked in the introduction: "Phonetic == s|z|S|Z") exceeds that of a comparable general purpose query language (e.g. a semantically similar SQL statement: SELECT desired_columns FROM items AS i, labels AS l WHERE i.unique_bundle_item_id = l.uniq_bundle_item_id AND l.label = 's' OR l.label = 'z' OR l.label = 's' OR l.label = 'S' OR l.label = 'Z'). This difference becomes even more apparent with more complex EQL statements, which can have very long, complicated and sometimes multi-expression SQL counterparts.
A problem which the EMU-SDMS does not explicitly address is the problem of cross-corpus searches. Different emuDBs may have varying annotation structures with varying semantics regarding the names or labels given to objects or annotation items in the databases. This means that it is very likely that a complex query formulated for a certain emuDB will fail when used to query other databases. If, however, the user either finds a query that works on every emuDB or adapts the query to extract the items she/he is interested in, a cross-corpus comparison is simple. As the result of a query and the corresponding data extraction routines are the same, regardless of database they where extracted from, these results are easily comparable. However, it is worth noting that the EMU-SDMS is completely indifferent to the semantics of labels and level names, which means it is the user’s responsibility to check if a comparison between databases is justifiable (e.g., are all segments containing the label “@” of the level “Phonetic”" in all emuDBs annotating the same type of phoneme?).
The examples and syntax descriptions used in this chapter have been adapted from examples by Cassidy and Harrington (2001) and Harrington and Cassidy (2002) and were largely extracted from the
EQLvignette of theemuRpackage. All of the examples were adapted to work with the supplied aeemuDB.↩︎