2 An overview of the EMU-SDMS1

The EMU Speech Database Management System (EMU-SDMS) is a collection of software tools which aims to be as close to an all-in-one solution for generating, manipulating, querying, analyzing and managing speech databases as possible. It was developed to fill the void in the landscape of software tools for the speech sciences by providing an integrated system that is centered around the R language and environment for statistical computing and graphics (R Core Team (2016)). This manual contains the documentation for the three software components wrassp, emuR and the EMU-webApp. In addition, it provides an in-depth description of the emuDB database format which is also considered an integral part of the new system. These four components comprise the EMU-SDMS and benefit the speech sciences and spoken language research by providing an integrated system to answer research questions such as: Given an annotated speech database, is the vowel height of the vowel @ (measured by its correlate, the first formant frequency) influenced by whether it appears in a strong or weak syllable?
This manual is targeted at new EMU-SDMS users as well as users familiar with the legacy EMU system. In addition, it is aimed at people who are interested in the technical details such as data structures/formats and implementation strategies, be it for reimplementation purposes or simply for a better understanding of the inner workings of the new system. To accommodate these different target groups, after initially giving an overview of the system, this manual presents a usage tutorial that walks the user through the entire process of answering a research question. This tutorial will start with a set of .wav audio and Praat .TextGrid (Boersma and Weenink (2016)) annotation files and end with a statistical analysis to address the hypothesis posed by the research question. The following Part I of this documentation is separated into six chapters that give an in-depth explanation of the various components that comprise the EMU-SDMS and integral concepts of the new system. These chapters provide a tutorial-like overview by providing multiple examples. To give the reader a synopsis of the main functions and central objects that are provided by EMU-SDMS’s main R package emuR, an overview of these functions is presented in Part II. Part III focuses on the actual implementation of the components and is geared towards people interested in the technical details. Further examples and file format descriptions are available in various appendices. This structure enables the novice EMU-SDMS user to simply skip the technical details and still get an in-depth overview of how to work with the new system and discover what it is capable of.
A prerequisite that is presumed throughout this document is the reader’s familiarity with basic terminology in the speech sciences (e.g., familiarity with the international phonetic alphabet (IPA) and how speech is annotated at a coarse and fine grained level). Further, we assume the reader has a grasp of the basic concepts of the R language and environment for statistical computing and graphics. For readers new to R, there are multiple, freely available R tutorials online (e.g., https://en.wikibooks.org/wiki/Statistical_Analysis:_an_Introduction_using_R/R_basics). R also has a set of very detailed manuals and tutorials that come preinstalled with R. To be able to access R’s own “An Introduction to R” introduction, simply type help.start() into the R console and click on the link to the tutorial.
2.1 The evolution of the EMU-SDMS
The EMU-SDMS has a number of predecessors that have been continuously developed over a number of years (e.g., Harrington et al. (1993), Cassidy and Harrington (1996), Cassidy and Harrington (2001), Bombien et al. (2006), Harrington (2010), John (2012)). The components presented here are the completely rewritten and newly designed, next incarnation of the EMU system, which we will refer to as the EMU Speech Database Management System (EMU-SDMS). The EMU-SDMS keeps most of the core concepts of the previous system, which we will refer to as the legacy system, in place while improving on things like usability, maintainability, scalability, stability, speed and more. We feel the redesign and reimplementation elevates the system into a modern set of speech and language tools that enables a workflow adapted to the challenges confronting speech scientists and the ever growing size of speech databases. The redesign has enabled us to implement several components of the new EMU-SDMS so that they can be used independently of the EMU-SDMS for tasks such as web-based collaborative annotation efforts and performing speech signal processing in a statistical programming environment. Nevertheless, the main goal of the redesign and reimplementation was to provide a modern set of tools that reduces the complexity of the tool chain needed to answer spoken language research questions down to a few interoperable tools. The tools the EMU-SDMS provides are designed to streamline the process of obtaining usable data, all from within an environment that can also be used to analyze, visualize and statistically evaluate the data.
Upon developing the new system, rather than starting completely from scratch it seemed more appropriate to partially reuse the concepts of the legacy system in order to achieve our goals. A major observation at the time was that the R language and environment for statistical computing and graphics (R Core Team (2016)) was gaining more and more traction for statistical and data visualization purposes in the speech and spoken language research community. However, R was mostly only used towards the end of the data analysis chain where data usually was pre-converted into a comma-separated values or equivalent file format by the user using other tools to calculate, extract and pre-process the data. While designing the new EMU-SDMS, we brought R to the front of the tool chain to the point just beyond data acquisition. This allows the entire data annotation, data extraction and analysis process to be completed in R, while keeping the key user requirements in mind. Due to personal experiences gained by using the legacy system for research puposes and in various undergraduate courses (course material usually based on Harrington (2010)), we learned that the key user requirements were data and database portability, a simple installation process, a simplified/streamlined user experience and cross-platform availability. Supplying all of EMU-SDMS’s core functionality in the form of R packages that do not rely on external software at runtime seemed to meet all of these requirements.
As the early incarnations of the legacy EMU system and its predecessors were conceived either at a time that predated the R system or during the infancy of R’s package ecosystem, the legacy system was implemented as a modular yet composite standalone program with a communication and data exchange interface to the R/Splus systems (see Cassidy and Harrington (2001) Section 3 for details). Recent developments in the package ecosystem of R such as the availability of the DBI package (R Special Interest Group on Databases (R-SIG-DB), Wickham, and Müller (2016)) and the related packages RSQLite and RPostgreSQL (Wickham, James, and Falcon (2014), Conway et al. (2016)), as well as the jsonlite package (Ooms (2014)) and the httpuv package (RStudio and Inc. (2015)), have made R an attractive sole target platform for the EMU-SDMS. These and other packages provide additional functional power that enabled the EMU-SDMS’s core functionality to be implemented in the form of R packages. The availability of certain R packages had a large impact on the architectural design decisions that we made for the new system.
The R code snippet below shows the simple installation process which we were able to achieve due to the R package infrastructure. Compared to the legacy EMU and other systems, the installation process of the entire system has been reduced to a single R command. Throughout this documentation we will try to highlight how the EMU-SDMS is also able to meet the rest of the above key user requirements.
# install the entire EMU-SDMS
# by installing the emuR package
install.packages("emuR")It is worth noting that throughout this manual R code snippets will be given in the form of the above snippet. These examples represent working R code that allow the reader to follow along in a hands-on manor and give a feel for what it is like working with the new EMU-SDMS.
2.2 EMU-SDMS: System architecture and default workflow
As was previously mentioned, the new EMU-SDMS is made up of four main components. The components are the emuDB format; the R packages wrassp and emuR; and the web application, the EMU-webApp, which is EMU-SDMS’s new GUI component. An overview of the EMU-SDMS’s architecture and the components’ relationships within the system is shown in Figure 2.1. In Figure 2.1, the emuR package plays a central role as it is the only component that interacts with all of the other components of the EMU-SDMS. It performs file and DB handling for the files that comprise an emuDB (see Chapter 4); it uses the wrassp package for signal processing purposes (see Chapter 8; and it can serve emuDBs to the EMU-webApp (see Chapter 9).
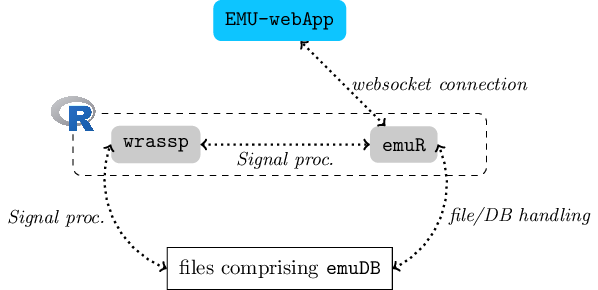
Figure 2.1: Schematic architecture of the EMU-SDMS
Although the system is made of four main components, the user largely only interacts directly with the EMU-webApp and the emuR package. A summary of the default workflow illustrating theses interactions can be seen below:
- Load database into current R session (
load_emuDB()). - Database annotation / visual inspection (
serve()). This opens up theEMU-webAppin the system’s default browser. - Query database (
query()). This is optionally followed byrequery_hier()orrequery_seq()as necessary (see Chapter 6 for details). - Get trackdata (e.g. formant values) for the result of a query (
get_trackdata()). - Prepare data.
- Visually inspect data.
- Carry out further analysis and statistical processing.
Initially the user creates a reference to an emuDB by loading it into their current R session using the load_emuDB() function (see step 1). This database reference can then be used to either serve (serve()) the database to the EMU-webApp or query (query()) the annotations of the emuDB (see steps 2 and 3). The result of a query can then be used to either perform one or more so-called requeries or extract signal values that correspond to the result of a query() or requery() (see step 4). Finally, the signal data can undergo further preparation (e.g., correction of outliers) and visual inspection before further analysis and statistical processing is carried out (see steps 5, 6 and 7). Although the R packages provided by the EMU-SDMS do provide functions for steps 4, 5 and 6, it is worth noting that the plethora of R packages that the R package ecosystem provides can and should be used to perform these duties. The resulting objects of most of the above functions are derived matrix or data.frame objects which can be used as inputs for hundreds if not thousands of other R functions.
2.3 EMU-SDMS: Is it something for you?
Besides providing a fully integrated system, the EMU-SDMS has several unique features that set it apart from other current, widely used systems (e.g., Boersma and Weenink (2016), Wittenburg et al. (2006), Fromont and Hay (2012), Rose et al. (2006), McAuliffe and Sonderegger (2016)). To our knowledge, the EMU-SDMS is the only system that allows the user to model their annotation structures based on a hybrid model of time-based annotations (such as those offered by Praat’s tier-based annotation mechanics) and hierarchical timeless annotations. An example of such a hybrid annotation structure is displayed in Figure 2.2. These hybrid annotations benefit the user in multiple ways, as they reduce data redundancy and explicitly allow relationships to be expressed across annotation levels (see Chapter @ref(chap:annot_struct_mod) for further information on hierarchical annotations and Chapter 6 on how to query these annotation structures).
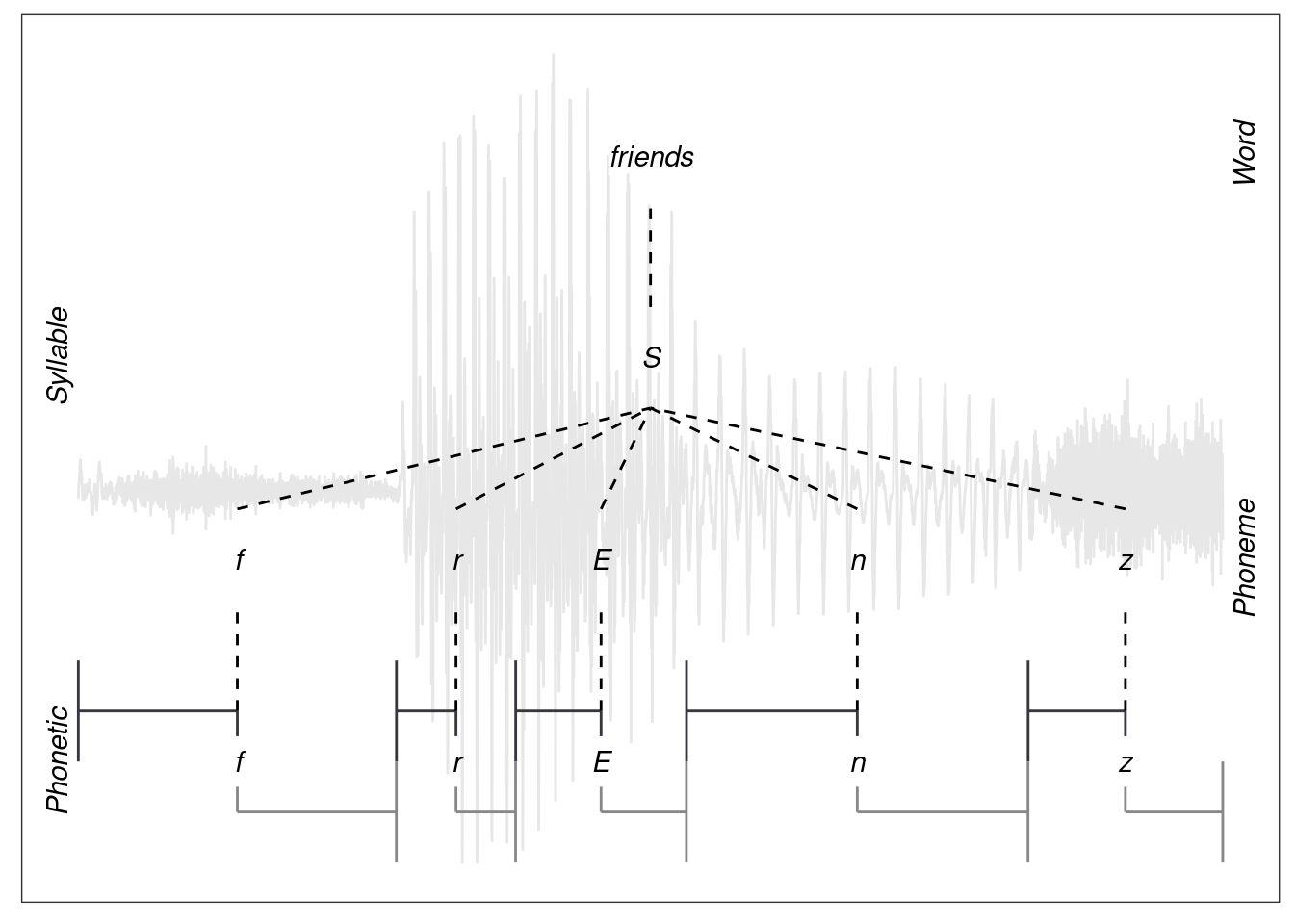
Figure 2.2: Example of a hybrid annotation combining time-based (Phonetic level) and hierarchical (Phoneme, Syllable, Text levels including the inter-level links) annotations.
Further, to our knowledge, the EMU-SDMS is the first system that makes use of a web application as its primary GUI for annotating speech. This unique approach enables the GUI component to be used in multiple ways. It can be used as a stand-alone annotation tool, connected to a loaded emuDB via emuR’s serve() function and used to communicate to other servers. This enables it to be used as a collaborative annotation tool. An in-depth explanation of how this component can be used in these three scenarios is given in Chapter 9.
As demonstrated in the default workflow of Section 2.2, an additional unique feature provided by EMU-SDMS is the ability to use the result of a query to extract derived (e.g., formants and RMS values) and complementary signals (e.g., electromagnetic articulography (EMA) data) that match the segments of a query. This, for example, aids the user in answering questions related to derived speech signals such as: Given an annotated speech database, is the vowel height of the vowel @ (measured by its correlate, the first formant frequency) influenced by whether it appears in a content or function word?. Chapter 3 gives a complete walk-through of how to go about answering this question using the tools provided by the EMU-SDMS.
The features provided by the EMU-SDMS make it an all-in-one speech database management solution that is centered around R. It enriches the R platform by providing specialized speech signal processing, speech database management, data extraction and speech annotation capabilities. By achieving this without relying on any external software sources except the web browser, the EMU-SDMS significantly reduces the number of tools the speech and spoken language researcher has to deal with and helps to simplify answering research questions. As the only prerequisite for using the EMU-SDMS is a basic familiarity with the R platform, if the above features would improve your workflow, the EMU-SDMS is indeed for you.
Sections of this chapter have been published in Winkelmann, Harrington, and Jänsch (2017)↩︎