5 The emuDB Format8

This chapter describes the emuDB format, which is the new database format of the EMU-SDMS, and shows how to create and interact with this format. The emuDB format is meant as a simple, general purpose way of storing speech databases that may contain complex, rich, hierarchical annotations as well as derived and complementary speech data. These different components will be described throughout this chapter, and examples will show how to generate and manipulate them. On designing the new EMU system, considerable effort went into designing an appropriate database format. We needed a format that was standardized, well structured, easy to maintain, easy to produce, easy to manipulate and portable.
We decided on the JavaScript Object Notation (JSON) file format9 as our primary data source for several reasons. It is simple, standardized, widely-used and text-based as well as machine and human readable. In addition, this portable text format allows expert users to (semi-) automatically process and/or generate annotations. Other tools such as the BAS Webservices (Kisler, Schiel, and Sloetjes 2012) and SpeechRecorder (Draxler and Jänsch 2004) have already taken advantage of being able to produce such annotations. Using database back-end options such as relational or graph databases of either the SQL or NoSQL variety as the primary data source for annotations would not directly permit other tools to produce annotations because intermediary exchange file formats would have to be defined to permit this functionality with these back-ends. Our choice of the JSON format was also guided by the decision to incorporate web technologies as part of the EMU-SDMS for which the JSON format is the de facto standard (see Chapter 9). Further, as the default encoding of the JSON format is UTF-8 the EMU-SDMS fully supports the Unicode character set for any user-defined string within an emuDB (e.g. level names and labels)10.
We chose to use the widely adopted Waveform Audio File Format (WAVE, or more commonly known as WAV due to its filename extension) as our primary media/audio format. Although some components of the EMU-SDMS, notably the wrassp package, can handle various other media/audio formats (see ?wrassp::AsspFileFormats for details) this is the only audio file format currently supported by every component of the EMU-SDMS. Nevertheless, the wrassp package can be utilized to convert files from one of it’s other supported file formats to the WAV format.11 Future releases of the EMU-SDMS might include the support of other media/audio formats.
In contrast to other systems, including the legacy EMU system, we chose to fully standardize the on-disk structure of speech databases with which the system is capable of working. This provides a standardized and structured way of storing speech databases while providing the necessary amount of freedom and separability to accommodate multiple types of data. Further, this standardization enables fast parsing and simplification of file-based error tracking and simplifies database subset and merging operations as well as database portability. An overview of all database interaction functions is given in Section 10.2.
5.1 Database design
An emuDB consists of a set of files and directories that adhere to a certain structure and naming convention (see Figure 5.1). The database root directory must include a single _DBconfig.json file that contains the configuration options of the database such as its level definitions, how these levels are linked in the database hierarchy and how the data is to be displayed by the graphical user interface. A detailed description of the _DBconfig.json file is given in Appendix 15.1.1. The database root directory also contains arbitrarily named session directories (except for the obligatory _ses suffix). These session directories can be used to group the recordings of a database in a logical manner. Sessions can be used, for example, to group all recordings from speaker AAA into a session called AAA_ses.
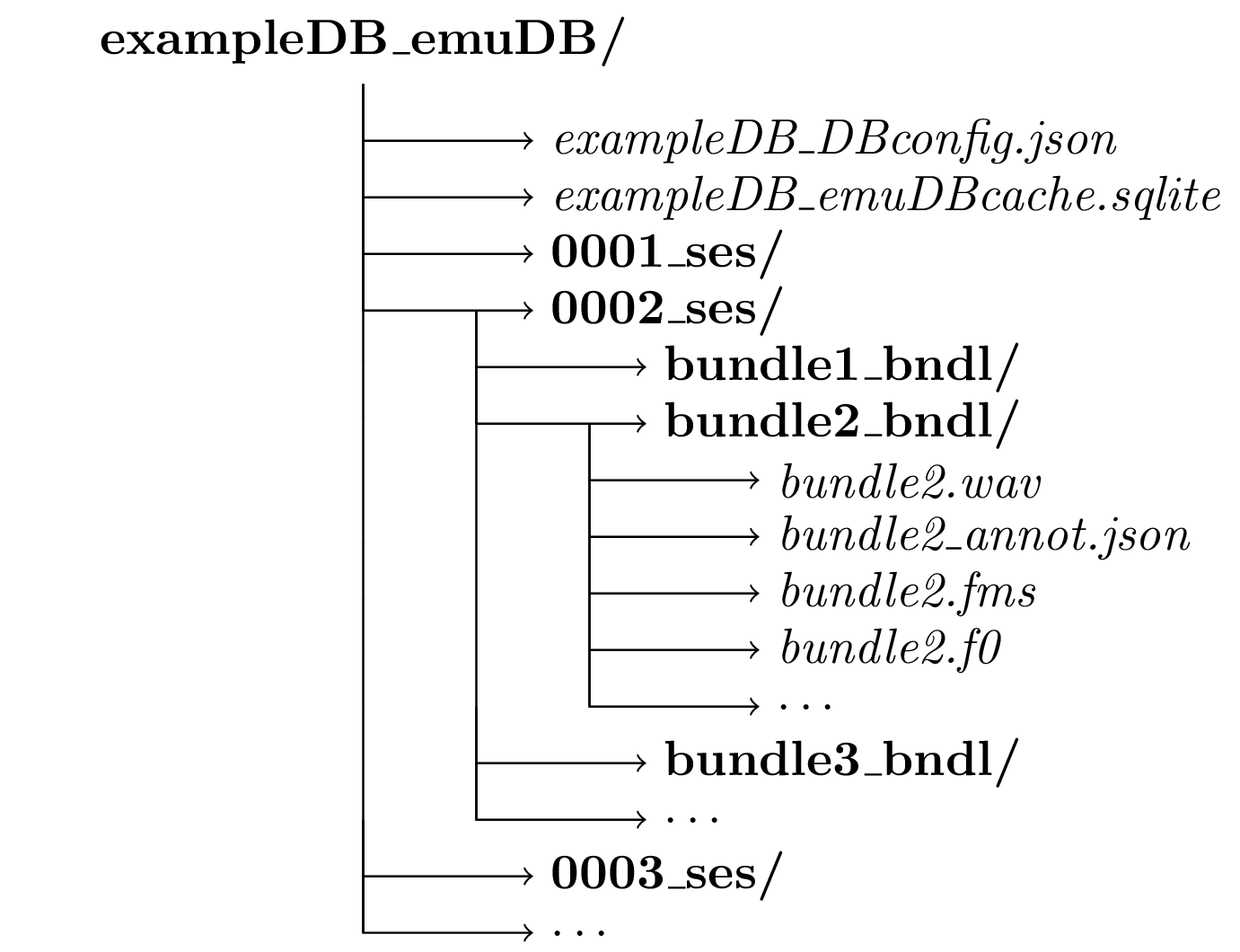
Figure 5.1: Schematic emuDB file and directory structure.
Each session directory can contain any number of _bndl directories (e.g., rec1_bndl rec2_bndl … rec9_bndl). All files belonging to a recording (i.e., all files describing the same timeline) are stored in the same bundle directory. This includes the actual recording (.wav) and can contain optional derived or supplementary signal files in the simple signal file format (SSFF) (Cassidy 2013) such as formants (.fms) or the fundamental frequency (.f0), both of which can be calculated using the wrassp package (see Chapter 8). Each bundle directory contains the annotation file (_annot.json) of that bundle (i.e., the annotations and the hierarchical linking information; see Appendix 15.1.2 for a detailed description of the file format). JSON schema files for all the JSON files types used have been developed to ensure the syntactic integrity of the database (see https://github.com/IPS-LMU/EMU-webApp/tree/master/dist/schemaFiles). All files within a bundle that are associated with that bundle must have the same basename as the _bndl directory prefix. For example, the signal file in bundle rec1_bndl must have the name rec1.wav to be recognized as belonging to the bundle. The optional _emuDBcache.sqlite file in the root directory (see Figure 5.1 contains the relational cache representation of the annotations of the emuDB (see Chapter 11 for further details). All files in an _bndl directory that do not follow the above naming conventions will simply be ignored by the database interaction functions of the emuR package.
5.2 Creating an emuDB
The two main strategies for creating emuDBs are either to convert existing databases or file collections to the new format or to create new databases from scratch where only .wav audio files are present. Chapter 3 gave an example of how to create an emuDB from an existing TextGrid file collection and other conversion routines are covered in Section 10.1. In this chapter we will focus on creating an emuDB from scratch with nothing more than a set of .wav audio files present.
5.2.1 Creating an emuDB from scratch
The R code snippet below shows how an empty emuDB is created in the directory provided by R’s tempdir() function. As can be seen by the output of the list.files() function, create_emuDB() creates a directory containing a _DBconfig.json file only.
# load package
library(emuR, warn.conflicts = F)
# create demo data in directory
# provided by tempdir()
create_emuRdemoData(dir = tempdir())
# create emuDB called "fromScratch"
# (verbose = F is only set to avoid additional output in manual)
create_emuDB(name = "fromScratch",
targetDir = tempdir(),
verbose = F)
# generate path to the empty fromScratch created above
dbPath = file.path(tempdir(), "fromScratch_emuDB")
# show content of empty fromScratch emuDB
list.files(dbPath)## [1] "fromScratch_DBconfig.json"5.2.2 Loading and editing an empty database
The initial step in manipulating and generally interacting with a database is to load the database into the current R session. The R code below shows how to load the fromScratch database and shows the empty configuration by displaying the output of the summary() function.
# load database
# (verbose = F is only set to avoid additional output in manual)
dbHandle = load_emuDB(dbPath, verbose = F)
# show summary of dbHandle
summary(dbHandle)## Name: fromScratch
## UUID: 95ab2da0-62d0-4281-95b7-57d3890cfcb6
## Directory: /tmp/RtmpToUWeQ/fromScratch_emuDB
## Session count: 0
## Bundle count: 0
## Annotation item count: 0
## Label count: 0
## Link count: 0
##
## Database configuration:
##
## SSFF track definitions:
## NULL
##
## Level definitions:
## NULL
##
## Link definitions:
## NULL# show class vector of dbHandle
class(dbHandle)## [1] "emuDBhandle"As can be seen in the above R code example, the class of a loaded emuDB is emuDBhandle. A emuDBhandle object is used to reference a loaded emuDB in the database interaction functions of the emuR package. In this chapter we will show how to use this emuDBhandle object to perform database manipulation operations. Most of the emuDB manipulation functions follow the following function prefix naming convention:
add_XXXadd a new instance ofXXX/set_XXXset the current instance ofXXX,list_XXXlist the current instances ofXXX/get_XXXget the current instance ofXXX,remove_XXXremove existing instances ofXXX.
5.2.3 Level definitions
Unlike other systems, the EMU-SDMS requires the user to formally define the annotation structure for the entire database. An essential structural element of any emuDB are its levels. A level is a more general term for what is often referred to as a tier. It is more general in the sense that people usually expect tiers to contain time information. Levels can either contain time information if they are of the type EVENT or of the type SEGMENT but are timeless if they are of the type ITEM (see Chapter 4 for further details). It is also worth noting that an emuDB distinguishes between the definition of an annotation structure element and the actual annotations. The definition of an annotation structure element such as a level definition is merely an entry in the _DBconfig.json file which specifies that this level is allowed to be present in the _annot.json files. The levels that are present in an _annot.json file, on the other hand, have to adhere to the definitions in the _DBconfig.json.
As the fromScratch database (already loaded) does not contain any annotation structural element definitions, the R code snippet below shows how a new level definition called Phonetic of type SEGMENT is added to the emuDB.
# show no level definitions
# are present
list_levelDefinitions(dbHandle)## NULL# add level defintion
add_levelDefinition(dbHandle,
name = "Phonetic",
type = "SEGMENT")
# show newly added level definition
list_levelDefinitions(dbHandle)## name type nrOfAttrDefs attrDefNames
## 1 Phonetic SEGMENT 1 Phonetic;The example below shows how a further level definition is added that will contain the orthographic word transcriptions for the words uttered in our recordings. This level will be of the type ITEM, meaning that elements contained within the level are sequentially ordered but do not contain any time information.
# add level definition
add_levelDefinition(dbHandle,
name = "Word",
type = "ITEM")
# list newly added level definition
list_levelDefinitions(dbHandle)## name type nrOfAttrDefs attrDefNames
## 1 Phonetic SEGMENT 1 Phonetic;
## 2 Word ITEM 1 Word;The function remove_levelDefinition() can also be used to remove unwanted level definitions. However, as we wish to further use the levels Phonetic and Word, we will not make use of this function here.
5.2.3.1 Attribute definitions
Each level definition can contain multiple attributes, the most common, and currently only supported attribute being a label (of type STRING). Thus it is possible to have multiple parallel labels (i.e., attribute definitions) in a single level. This means that a single annotation item instance can contain multiple labels while sharing other properties such as the start and duration information. This can be useful when modeling certain types of data. An example of this would be the Phonetic level created above. It is often the case that databases contain both the phonetic transcript using IPA UTF-8 symbols as well as a transcript using Speech Assessment Methods Phonetic Alphabet (SAMPA) symbols. To avoid redundant time information, both of these annotations can be stored on the same Phonetic level using multiple attribute definitions (i.e., parallel labels). The next R code snippet shows the current attribute definitions of the Phonetic level.
# list attribute definitions of 'Phonetic' level
list_attributeDefinitions(dbHandle,
levelName = "Phonetic")## name level type hasLabelGroups hasLegalLabels
## 1 Phonetic Phonetic STRING FALSE FALSEEven though no attribute definition has been added to the Phonetic level, it already contains an attribute definition that has the same name as its level. This attribute definition represents the obligatory primary attribute of that level. As every level must contain an attribute definition that has the same name as its level, it is automatically added by the add_levelDefinition() function. To follow the above example, the next R code snippet adds a further attribute definition to the Phonetic level that contains the SAMPA versions of our annotations.
# add
add_attributeDefinition(dbHandle,
levelName = "Phonetic",
name = "SAMPA")## NULL# list attribute definitions of 'Phonetic' level
list_attributeDefinitions(dbHandle,
levelName = "Phonetic")## name level type hasLabelGroups hasLegalLabels
## 1 Phonetic Phonetic STRING FALSE FALSE
## 2 SAMPA Phonetic STRING FALSE FALSE5.2.3.2 Legal labels
As can be inferred from the columns hasLabelGroups and hasLegalLabels of the output of the above list_attributeDefinitions() function, attribute definitions can also contain two further optional fields. The legalLabels field contains an array of strings that specifies the labels that are legal (i.e., allowed or valid) for the given attribute definition. As the EMU-webApp does not allow the annotator to enter any labels that are not specified in this array, this is a simple way of assuring that a level has a consistent label set. The following R code snippet shows how the set_legalLabels and get_legalLabels functions can be used to specify a legal label set for the primary Word attribute definition of the Word level.
# define allowed word labels
wordLabels = c("amongst", "any", "are",
"always", "and", "attracts")
# show empty legal labels
# for "Word" attribute definition
get_legalLabels(dbHandle,
levelName = "Word",
attributeDefinitionName = "Word")## [1] NA# set legal labels values
# for "Word" attribute definition
set_legalLabels(dbHandle,
levelName = "Word",
attributeDefinitionName = "Word",
legalLabels = wordLabels)
# show recently added legal labels
# for "Word" attribute definition
get_legalLabels(dbHandle,
levelName = "Word",
attributeDefinitionName = "Word")## [1] "amongst" "any" "are" "always" "and" "attracts"5.2.3.3 Label groups
A further optional field is the labelGroups field. It contains specifications of groups of labels that can be referenced by a name given to the group while querying the emuDB. The R code below shows how the add_attrDefLabelGroup() function is used to add two label groups to the Phonetic attribute definition. One of the groups is used to reference a subset of longVowels and the other to reference a subset of shortVowels on the Phonetic level.
# add long vowels label group
add_attrDefLabelGroup(dbHandle,
levelName = "Phonetic",
attributeDefinitionName = "Phonetic",
labelGroupName = "longVowels",
labelGroupValues = c("i:", "u:"))
# add short vowels label group
add_attrDefLabelGroup(dbHandle,
levelName = "Phonetic",
attributeDefinitionName = "Phonetic",
labelGroupName = "shortVowels",
labelGroupValues = c("i", "u", "@"))
# list current label groups
list_attrDefLabelGroups(dbHandle,
levelName = "Phonetic",
attributeDefinitionName = "Phonetic")## name values
## 1 longVowels i:; u:
## 2 shortVowels i; u; @# query all short vowels
# Note that the result of this query
# is empty as no annotations are present
# in the 'fromScratch' emuDB
query(dbHandle, "Phonetic == shortVowels")## # A tibble: 0 x 16
## # … with 16 variables: labels <chr>, start <dbl>, end <dbl>, db_uuid <chr>,
## # session <chr>, bundle <chr>, start_item_id <int>, end_item_id <int>,
## # level <chr>, attribute <chr>, start_item_seq_idx <int>,
## # end_item_seq_idx <int>, type <chr>, sample_start <int>, sample_end <int>,
## # sample_rate <int>For users who are familiar with or transitioning from the legacy EMU system, it is worth noting that the label groups correspond to the unfavorably named Legal Labels entries of the GTemplate Editor (i.e., legal entries in the .tpl file) of the legacy system. In the new system the legalLabels entries specify the legal or allowed label values of attribute definitions while the labelGroups specify groups of labels that can be referenced by the names given to the groups while performing queries.
A new feature of the EMU-SDMS is the possibility of defining label groups for the entire emuDB as opposed to a single attribute definition (see ?add_labelGroups for further details). This avoids the redundant definition of label groups that should span multiple attribute definitions (e.g., a longVowels subset that is to be queried on a level called Phonetic_1 as well as a level called Phonetic_2).
5.2.4 Link definitions
An essential and very powerful conceptual and structural element of any emuDB is its hierarchy. Using hierarchical structures is highly recommended but not a must. Hierarchical annotations allow for complex, rich data modeling and are often cleaner representations of the annotations at hand. As Chapter 4 contains in-depth explanations of the annotation modeling capabilities of the EMU-SDMS and Chapter 6 shows how these structures can be queried using emuR’s query mechanics, this chapter will omit an explanation of hierarchical annotation structures. The following R code shows how a ONE_TO_MANY relationship between the Word and Phonetic in the form of a link definition is added to an emuDB.
# show that currently no link definitions
# are present
list_linkDefinitions(dbHandle)## NULL# add new "ONE_TO_MANY" link definition
# between "Word" and "Phonetic" levels
add_linkDefinition(dbHandle,
type = "ONE_TO_MANY",
superlevelName = "Word",
sublevelName = "Phonetic")
# show newly added link definition
list_linkDefinitions(dbHandle)## type superlevelName sublevelName
## 1 ONE_TO_MANY Word PhoneticA schematic of the simple hierarchical structure of the fromScratch created by the above R code is displayed in Figure 5.2.

Figure 5.2: A schematic representation of the simple hierarchical structure of the fromScratch created by the add_linkDefinition() function call in above R code snippet.
5.2.5 File handling
The previous sections of this chapter defined the simple structure of the fromScratch emuDB. An essential element that is still missing from the emuDB is the actual audio speech data12. The following R code example shows how the import_mediaFiles() function can be used to import audio files, referred to as media files in the context of an emuDB, into the fromScratch emuDB.
# get the path to directory containing .wav files
wavDir = file.path(tempdir(), "emuR_demoData", "txt_collection")
# Import media files into emuDB session called fromWavFiles.
# Note that the txt_collection directory also contains .txt files.
# These are simply ignored by the import_mediaFiles() function.
# (verbose = F is only set to avoid additional output in manual)
import_mediaFiles(dbHandle,
dir = wavDir,
targetSessionName = "fromWavFiles",
verbose = F)
# list session
list_sessions(dbHandle)## name
## 1 fromWavFiles# list bundles
list_bundles(dbHandle)## # A tibble: 7 x 2
## session name
## <chr> <chr>
## 1 fromWavFiles msajc003
## 2 fromWavFiles msajc010
## 3 fromWavFiles msajc012
## 4 fromWavFiles msajc015
## 5 fromWavFiles msajc022
## 6 fromWavFiles msajc023
## 7 fromWavFiles msajc057# show first few files in the emuDB
list_files(dbHandle)## # A tibble: 14 x 4
## session bundle file absolute_file_path
## <chr> <chr> <chr> <chr>
## 1 fromWavFi… msajc0… msajc003_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 2 fromWavFi… msajc0… msajc003.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 3 fromWavFi… msajc0… msajc010_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 4 fromWavFi… msajc0… msajc010.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 5 fromWavFi… msajc0… msajc012_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 6 fromWavFi… msajc0… msajc012.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 7 fromWavFi… msajc0… msajc015_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 8 fromWavFi… msajc0… msajc015.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 9 fromWavFi… msajc0… msajc022_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 10 fromWavFi… msajc0… msajc022.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 11 fromWavFi… msajc0… msajc023_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 12 fromWavFi… msajc0… msajc023.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 13 fromWavFi… msajc0… msajc057_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 14 fromWavFi… msajc0… msajc057.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…The import_mediaFiles() call above added a new session called fromWavFiles to the fromScratch emuDB containing a new bundle for each of the imported media files. The annotations of every bundle, despite containing empty levels, adhere to the structure specified above. This means that every _annot.json file created contains an empty Word and Phonetic level array and the links array is also empty.
The emuR package also provides a mechanism for adding files to preexisting bundle directories, as this can be quite tedious to perform manually due to the nested directory structure of an emuDB. The following R code shows how preexisting .zcr files that are produced by wrassp’s zcrana() function can be added to the preexisting session and bundle structure. As the directory referenced by wavDir does not contain any .zcr files, the next R code example first creates them and then adds them to the emuDB (see Chapter 8 for further details).
# load wrassp package
library(wrassp)## Loading required package: tibble# list all wav files in wavDir
wavFilePaths = list.files(wavDir,
pattern = ".*.wav",
full.names = TRUE)
# calculate zero-crossing-rate files
# using zcrana function of wrassp package
# (verbose = F is only set to avoid additional output in manual)
zcrana(listOfFiles = wavFilePaths,
verbose = FALSE)## [1] 7# add zcr files to emuDB
add_files(dbHandle,
dir = wavDir,
fileExtension = "zcr",
targetSessionName = "fromWavFiles")
# show first few files in emuDB
list_files(dbHandle)## # A tibble: 21 x 4
## session bundle file absolute_file_path
## <chr> <chr> <chr> <chr>
## 1 fromWavFi… msajc0… msajc003_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 2 fromWavFi… msajc0… msajc003.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 3 fromWavFi… msajc0… msajc003.zcr /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 4 fromWavFi… msajc0… msajc010_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 5 fromWavFi… msajc0… msajc010.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 6 fromWavFi… msajc0… msajc010.zcr /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 7 fromWavFi… msajc0… msajc012_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 8 fromWavFi… msajc0… msajc012.wav /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 9 fromWavFi… msajc0… msajc012.zcr /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## 10 fromWavFi… msajc0… msajc015_an… /tmp/RtmpToUWeQ/fromScratch_emuDB/fromWavFil…
## # … with 11 more rows5.2.6 SSFF track definitions
A further important structural element of any emuDB is use of the so-called SSFF tracks, which are often simply referred to as tracks. These SSFF tracks reference data that is stored in the SSFF file format (see Appendix 15.1.3 for a detailed description of the file format) within the _bndl directories. The two main types of data are:
- complementary data that was acquired during the recording such as by EMA or EPG; or
- derived data, that is data that was calculated from the original audio signal such as formant values and their bandwidths or the short-term Root Mean Square amplitude of the signal.
As Section 8.7 covers how the SSFF file output of a wrassp function can be added to an emuDB, an explanation will be omitted here. The following R code snippet shows how the .zcr files added in the R example above can be added as an SSFF track definition (see Chapter 8 for further details).
# show that no SSFF track definitions
# are present
list_ssffTrackDefinitions(dbHandle)## NULL# add SSFF track definition to emuDB
add_ssffTrackDefinition(dbHandle,
name = "zeroCrossing",
columnName = "zcr",
fileExtension = "zcr")
# show newly added SSFF track definition
list_ssffTrackDefinitions(dbHandle)## name columnName fileExtension
## 1 zeroCrossing zcr zcr5.2.7 Configuring the EMU-webApp and annotating the emuDB
As previously mentioned, the current fromScratch emuDB contains only empty levels. In order to start annotating the database, the EMU-webApp has to be configured to display the desired information. Although the configuration of the EMU-webApp is stored in the _DBconfig.json file and is therefore a part of the emuDB format, here we will omit an explanation of the extensive possibilities of configuring the web application (see Chapter 9 for an in-depth explanation). The R code snippet below shows how the Phonetic level is added to the level canvases order array of the default perspective.
# show empty level canvases order
get_levelCanvasesOrder(dbHandle, perspectiveName = "default")## NULL# set level canvases order to display "Phonetic" level
set_levelCanvasesOrder(dbHandle,
perspectiveName = "default",
order = c("Phonetic"))
# show newly added level canvases order
get_levelCanvasesOrder(dbHandle, perspectiveName = "default")## [1] "Phonetic"As a final step before beginning the annotation process, the fromScratch emuDB has to be served to the EMU-webApp for annotation and visualization purposes. The code below shows how this can be achieved using the serve() function.
# serve "fromScratch" emuDB to the EMU-webApp
serve(dbHandle)5.3 Conclusion
This chapter introduced the elements that comprise the new emuDB format and provided a practical overview of the essential database interaction functions provided by the emuR package. We feel the emuDB format provides a general purpose, flexible approach to storing speech databases with the added benefit of being able to directly manipulate and analyse these databases using the tools provided by the EMU-SDMS.
Sections of this chapter where published in Winkelmann, Harrington, and Jänsch (2017) and some examples taken from the
emuDBvignette of theemuRpackage.↩︎JSON schema files available here https://github.com/IPS-LMU/EMU-webApp/tree/master/dist/schemaFiles↩︎
According to the JSON specification (see https://json.org/) the only characters that have to be escaped within a JSON string are: ’’ (as this marks the start/end of a string), \ (as this is the escape character) or control-characters (\b = backspace, \f = form feed, \n = new line, \r = carriage return, \t = tab). Unicode characters in their hexadecimal form using the \u followed by for-hex-digits may also be used.↩︎
However, if things like resampeling are required we suggest using other tools such as the freely available Sound eXchange (SoX) command line tool (see http://sox.sourceforge.net/) to perform these operation↩︎
As the
EMU-webAppcurrently only supports mono 16 Bit.wavaudio files, we currently recommend using this format only.↩︎